搜索引擎工作过程非常复杂,今天和大家分享一下我所了解的百度蜘蛛是怎么实现网页收录的。
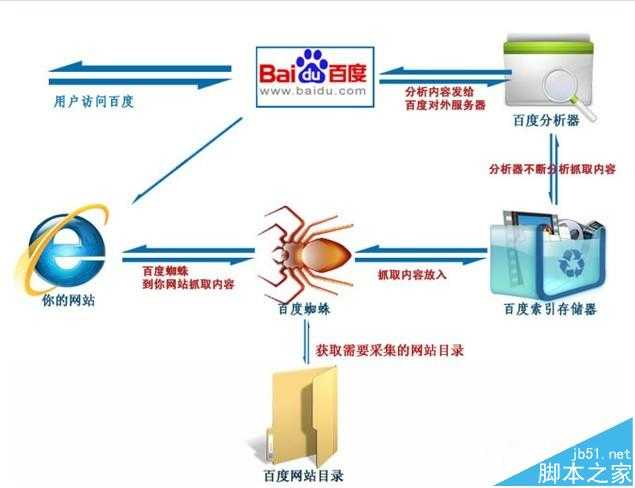
搜索引擎工作大致可以分为四个过程。
1、蜘蛛爬行抓取。
2、信息过滤。
3、建立网页关键词索引。
4、用户搜索输出结果。
蜘蛛爬行抓取
当百度蜘蛛来到一个页面时,它会跟踪页面上的链接,从这个页面爬行到下一个页面,就好像一个递归过程,这样常年累月,不止疲倦的工作。比如蜘蛛来到了我的博客首页http://blog.sina.com.cn/netSEOer,它会先读取根目录下的robots.txt文件,如果没有禁止搜索引擎抓取,那么蜘蛛就开始针对网页上的链接,进行逐一跟踪爬行。比如我的置顶文章“SEO概述|什么是SEO SEO到底是干嘛的”,引擎就会多进程式的来到这篇文章所在的网页抓取信息,如此循坏,没有终结。
信息过滤
为了避免重复爬行和抓取网址,搜索引擎会有一个记录已爬行和未被爬行的地址库,如果你有一个新网站时,你可以去百度官网提交网站的网址,引擎就会记录它,并把它归类到未爬行的网址,然后蜘蛛就会根据这个表格,从数据库中提取URL,访问并抓取页面。
蜘蛛并不会收录所有的页面,它要经过严格检测。当蜘蛛在爬行和抓取一个网页的内容时,会进行一定程度的复制内容检测,如果网页所在的网站权重低,而且大部分文章都是抄袭来的话,蜘蛛就很可能不喜欢你的网站了,不在继续爬行,也就不收录你的网站。
建立网页关键词索引
当蜘蛛抓取了一个页面之后,首先会对页面文字内容进行分析。通过分词技术,将网页的内容简化到关键词,并把关键词和对应的网址制成表格建立索引。
索引又有正向索引和反向索引,正向索引是把网页内容对应的关键词,反向是关键词对应的网页信息。
输出结果
当用户搜索了某个关键词之后,就会通过前面建立的索引表进行关键词匹配,通过反向索引表找到关键词对应的页面,通过引擎对网页综合评分计算以后,根据网页的评分来决定网页的先后顺序排名。
相关推荐:
网站优化 百度蜘蛛到底喜欢什么?
怎么查询ip是否为百度蜘蛛ip? tracert指令的使用方法
百度,蜘蛛收录
更新日志
- 证声音乐图书馆《真夏派对 x 浩室》[320K/MP3][67.19MB]
- 张镐哲.1994-无助【波丽佳音】【WAV+CUE】
- Relic.2024-浮在虛无的诗意【SEEAHOLE】【FLAC分轨】
- 群星.2001-台语(原主唱)排行总冠军黄金典藏版6CD【柯达唱片】【WAV+CUE】
- 证声音乐图书馆《真夏派对 x 浩室》[FLAC/分轨][379.1MB]
- 徐良《东西世界》[WAV+CUE][1.1G]
- 证声音乐图书馆《真夏派对 x 迪斯可》[320K/MP3][67.9MB]
- TheDutchSwingCollegeBand-JubileeConcert(LiveRemastered2024)(1980)[24Bit-96kHz]FLAC
- 永恒英文金曲精选6《TheBestOfEverlastingFavouritesVol.6》[WAV+CUE]
- ABC唱片-鲍比达·新民乐《满江红》[APE+CUE]
- 许嵩.2014-不如吃茶去【海蝶】【WAV+CUE】
- 周笔畅.2024-HAVE.A.GOOD.NIGHT【SN.Music】【FLAC分轨】
- 周笔畅.2024-HAVE.A.NICE.DAY【SN.Music】【FLAC分轨】
- 证声音乐图书馆《真夏派对 x 迪斯可》[FLAC/分轨][380.78MB]
- 证声音乐图书馆《星空下 爵士钢琴》[320K/MP3][65.88MB]